5.Mapping
我们首先使用 bowtie 软件将 reads 比对到基因组,完成mapping后可视化比对出的结果。
1) Pipeline
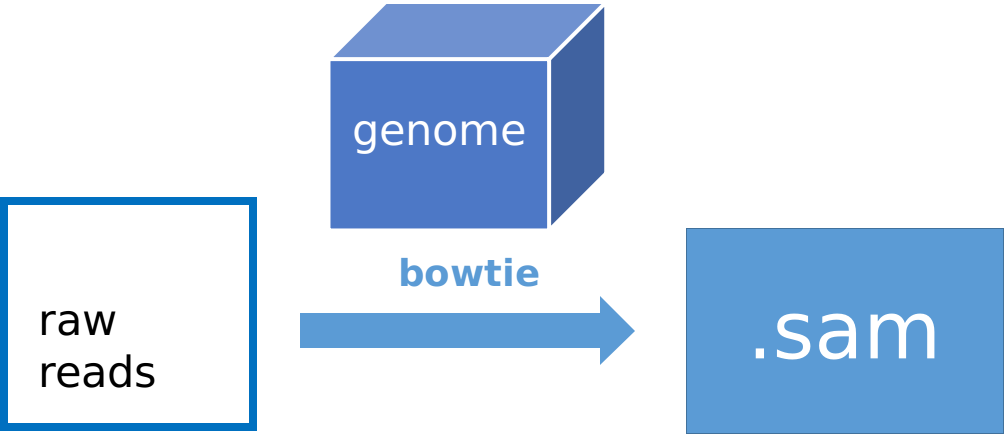
2) Data Structure
2a) getting software & data
install software (already available in Docker)
data
- 我们使用酵母和e.coli 的数据,位于 Docker 中的
/home/test/mapping。 - 我们从 这里 下载了 bowtie 提供的酵母和 e.coli 基因组 index,分别位于 Docker 中的
/home/test/mapping/BowtieIndex和/home/test/mapping/bowtie-src/indexes。
- 我们使用酵母和e.coli 的数据,位于 Docker 中的
2b) input
| Format | Description | Notes |
|---|---|---|
.fq |
存储 raw reads | FASTQ Format |
例如:
@EAS54_6_R1_2_1_413_324
CCCTTCTTGTCTTCAGCGTTTCTCC
+
;;3;;;;;;;;;;;;7;;;;;;;88
FASTQ format stores sequences and Phred qualities in a single file. It is concise and compact. FASTQ is first widely used in the Sanger Institute and therefore we usually take the Sanger specification and the standard FASTQ format, or simply FASTQ format. Although Solexa/Illumina read file looks pretty much like FASTQ, they are different in that the qualities are scaled differently. In the quality string, if you can see a character with its ASCII code higher than 90, probably your file is in the Solexa/Illumina format.
2c) output
| Format | Description | Notes |
|---|---|---|
.sam |
mapping 结果 | - |
.bed |
Tab分隔, 便于其它软件(例如 IGB )处理 | - |
bed文件格式:
- chrom: The name of the chromosome (e.g. chr3, chrY, chr2_random) or scaffold (e.g. scaffold10671).
- chromStart: The starting position of the feature in the chromosome or scaffold. The first base in a chromosome is numbered 0.
- chromEnd: The ending position of the feature in the chromosome or scaffold. The chromEnd base is not included in the display of the feature. For example, the first 100 bases of a chromosome are defined as chromStart=0, chromEnd=100, and span the bases numbered 0-99.
- name (optional): Defines the name of the BED line. This label is displayed to the left of the BED line in the Genome Browser window when the track is open to full display mode or directly to the left of the item in pack mode.
- score (optional): A score between 0 and 1000.
3) Running Steps
首先进入到容器(在自己电脑的 Terminal 中运行,详情请参见 这里):
docker exec -it bioinfo_tsinghua bash
以下步骤均在 /home/test/mapping/ 下进行:
cd /home/test/mapping/
3a) mapping
bowtie -v 2 -m 10 --best --strata BowtieIndex/YeastGenome -f THA1.fa -S THA1.sam
bowtie -v 1 -m 10 --best --strata bowtie-src/indexes/e_coli \
-q e_coli_1000_1.fq -S e_coli_1000_1.sam
-vreport end-to-end hits with less than v mismatches; ignore qualities-msuppress all alignments if more than m exist (def: no limit)-Mlike-m, but reports 1 random hit (MAPQ=0) (requires--best)--besthits guaranteed best stratum; ties broken by quality--stratahits in sub-optimal strata aren't reported (requires--best)-fraw reads文件 (FASTA)-qraw reads 文件(FASTQ)-S输出文件名,格式为.sam格式
3b) 可视化比对结果
我们之后可以可视化比对出的结果。常用的软件和网站包括IGV和UCSC。将sam处理成Bed格式,方便后续可视化处理。IGV 清华云下载 ,IGV 网站下载
3b.1)格式转化
perl sam2bed.pl THA1.sam > THA1.bed
3b.2)过滤文件
上传 .bed 文件到 Genome Browser 浏览时,如果文件过大,或者MT染色体不识别,可以用如下方法:
grep -v chrmt THA1.bed > THA1_new.bed #输出一个不含chromosome MT的文件
grep $'chrIV\t' THA1.bed > THA1_chrIV.bed #输出一个只有chromosome IV的文件
# 将文件拷入共享文件夹下面,文件就共享在桌面下的 bioinfo_tsinghua_share (如果有问题,请看Getting Started 创建并运行容器)
cp THA1_new.bed ~/share
cp THA1_chrIV.bed ~/share
3b.3)如何使用 UCSC genome browser
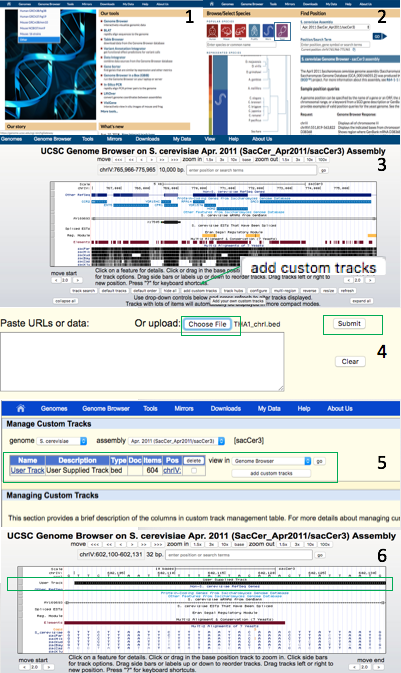
Tips:
- 对于处理好的测序数据(bigWig,BAM,bigBed),UCSC仅支持通过提供URL链接或直接输入。
- 在比较不同样本的数据时,需要根据样本本身测序深度的不同来对纵坐标进行调整,从而保证该区域/位点测序数据能够显示完整并且可以相互比较。
- 有时,用 bedtools genomecov scale之后的 bigwig 文件纵坐标仍然会出现显示不完整等现象,此时需要手动调整下。
3b.4)如何使用 IGV genome browser IGV 清华云下载 ,IGV 网站下载
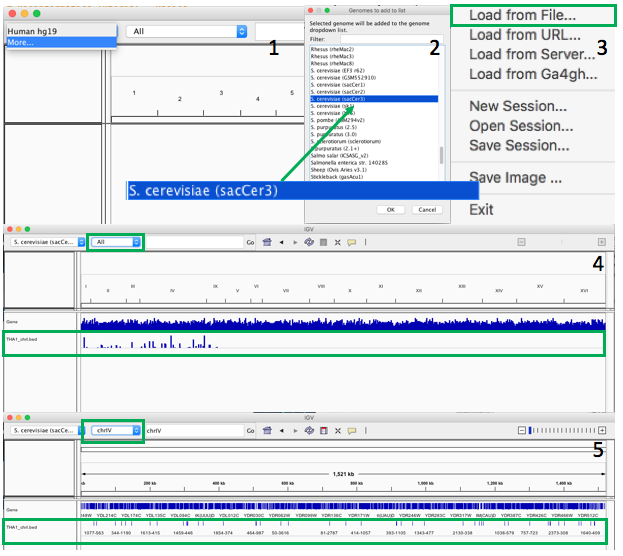
- 演示视频
- 演示视频
4) Tips/Utilities
更多基因组文件格式详见 http://genome.ucsc.edu/FAQ/FAQformat.html。
5) Homework and more
- 将
THA2.famap 到BowtieIndex/YeastGenome上,得到THA2.sam。 - 将
e_coli_500.fqmap 到bowtie-src/indexes/e_coli上,得到e_coli_500.sam。 - 将上面两个结果均转换为
.bed文件。 从上一步得到的
THA2.bed中筛选出- 一个不含chromosome V 的文件
一个只有chromosome XII 的文件
(提交各步骤代码并汇报最后一步输出文件的行数)
休息一会
Illumina & Affymetrix

“Illumina公司的市场数据实在是非常美妙的东西。”拥有个人博客的基因研究人员丹尼尔·麦克阿瑟(Daniel Macarthur)说,“它是如此地纯净,到了令人吃惊的地步。” 当Illumina公司目前的股价净值比高达84倍的时候,高盛仍然建议买入,声称该公司很有可能继续保持其在DNA测序领域里的领导地位。
Illumina毫无疑问是这个时代科技公司的榜样。在生物学仪器制造领域,跟Thermo,Life等拥有几十年历史的公司相比,1998年起源于加州圣地亚哥的Illumina显然还是个年轻小伙。从1999年25个人的规模、130万美元的年营业额,到2013年超过3200人的规模、14.21亿美元的年营业额。
今天,Illumina公司几乎垄断了所有的二代测序(NGS:Next Generation Sequencing)市场。但是,Illumina公司最初是一家生产DNA芯片(microarray chip)的公司,这是一种侦测DNA变异的早期技术。而且,那时的Illumina公司还落后于该市场缔造者Affymetrix公司。
Illumina今天已经赶超了Affymetrix,并将其远远抛之脑后。最主要的原因,在于它从DNA芯片到DNA测序上的成功转型。Illumina公司的成功,很多人归功于其CEO,Jay Flatley,在战略上的敏锐。他很可能称得上是生物科技领域里的最佳CEO。2006年,Flatley说服Illumina公司董事会以6亿美元的价格收购了一家叫Solexa的开发NGS技术的小公司(同类型的NGS技术公司还有454等,因为其技术、成本和市场上的弱势,今天已经很少有人听说了),借此大力押注DNA测序。
如今,illumina在二代测序(NGS:Next Generation Sequencing)乃至整个测序市场占据领导地位。引用illumina官方说法:“世界上90%以上的测序数据都由illumina仪器产生”,不较真的话,这句话确实在某种程度上反应了illumina雄踞NGS市场的现状(下图是illumina 测序产品发布时间线) 。尤其是HiSeq系列测序仪的问世,以通量高,产量大,生产规模著称,能够快速、经济的进行大规模平行测序,在大型全基因组测序,全转录组,全外显子组测序,靶向基因测序方面优势明显。

另外,illumina团队把现有的所有二代测序建库技术都收集并整理成标准,免费查看。这是Sequence Method Explorer的网址: